

.png)


.png)
Not a week goes by without another online debate about storage format wars, specifically between Delta Lake and Apache IcebergTM. Yet amidst all the discussion about performance benchmarks, portability, and lock-in, the real battle has always been about where and how to run these formats.
At Koantek, we work with enterprises navigating complex platform shifts, and we’re seeing firsthand why Databricks is emerging as the definitive platform for Apache Iceberg.
Wherever you are in your data journey, whether you're choosing your first open-source table format, migrating from a legacy platform, or expanding your existing Databricks stack, the clear path is to choose a platform that makes format choice an implementation detail, not a barrier.
And yes, we also need to talk about those platforms that monetize proprietary storage formats while straddling the line between openness and closedness. While they may do this under the debatable guise of improved performance or security, their ulterior motive is to build moats, create friction to deter you from leaving, and lock you in.
Why This Decision Matters Now
In June 2024, Databricks made a $1 billion+ bet on the future of open data formats by acquiring Tabular, the company founded by the creators of Apache Iceberg. This acquisition was a declaration that the format wars are over, with the battle now moving up the stack to the catalogs and the platforms themselves.
Since then, Databricks has quietly but decisively built the infrastructure to support Delta Lake and Apache Iceberg from a single runtime. Iceberg v3 landed in May 2025, introducing Deletion Vectors, Row Lineage, VARIANT, and Geospatial types, all features that converge the Delta and Iceberg specifications. Databricks has already begun integrating v3 into the Data Intelligence Platform, eliminating the last technical reasons to choose one format over the other.
Every day spent waiting to embrace open table formats is another day of:
- Paying for redundant data copies
- Running inefficient ETL jobs on expensive compute
- Accumulating technical debt that compounds over time
- Delaying AI and ML innovations that require unified data access
Path A: Choosing Your First Open Format
"I need to pick between Delta and Iceberg."
The liberating truth is that you don't need to choose.
The False Choice
The debate over which format to adopt assumes you must pick one and live with the consequences. This made sense when formats were islands. Delta tables can already be read by Iceberg clients using UniForm.
Many Koantek clients begin here: looking for a future-proof, open foundation. In nearly all cases, we guide them to Delta with UniForm, delivering optionality without tradeoffs.
You write your data once using Delta Lake, benefiting from its 1.7× performance advantage and mature feature set, and UniForm automatically generates Iceberg metadata alongside it without additional copies, ETL jobs, or synchronization delays.
How UC Managed Iceberg Delivers Open Interoperability Today
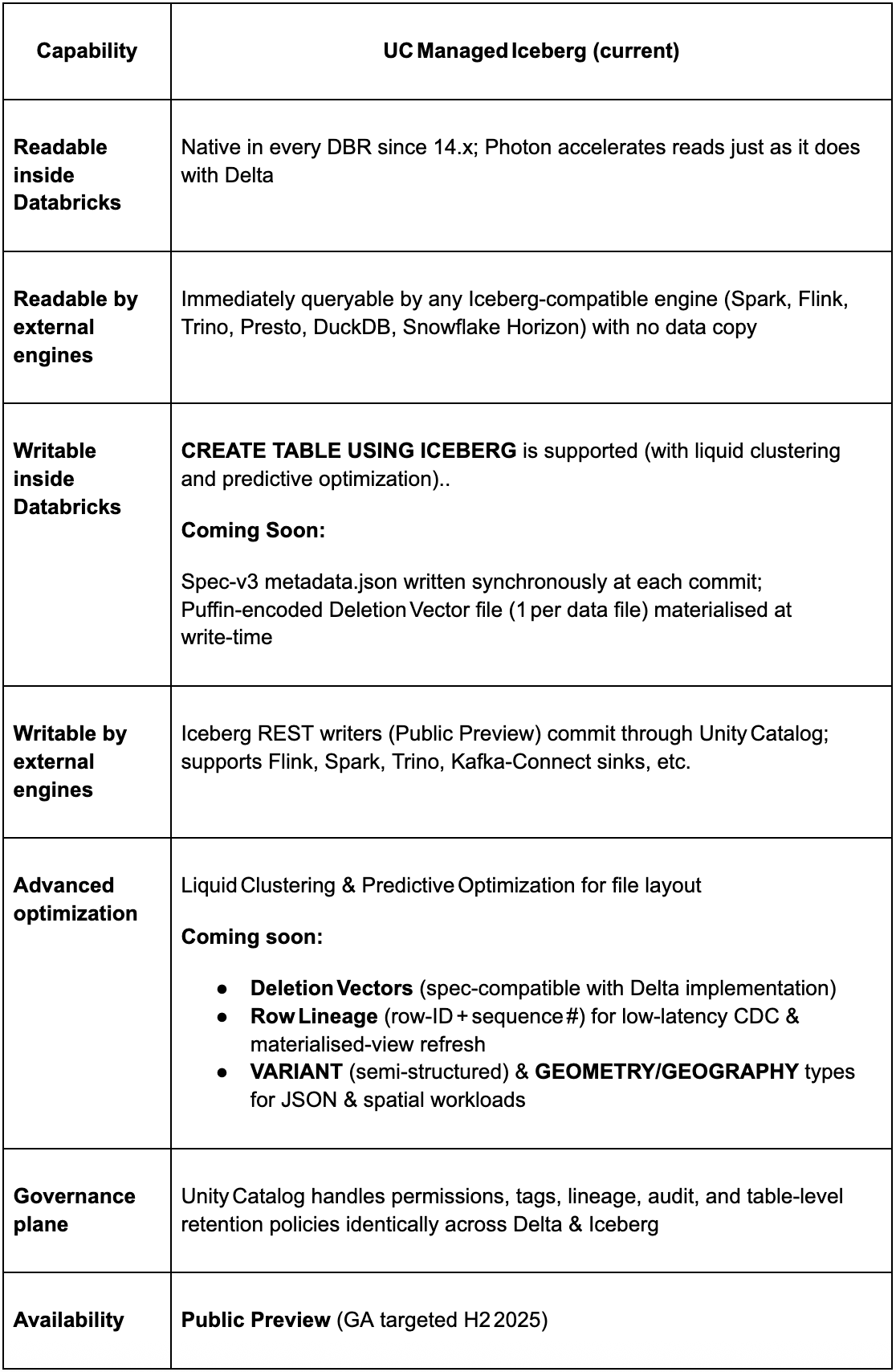
Roadmap context — Delta & UniForm
The Delta and Apache Iceberg communities are pushing the two formats even closer towards full interoperability. Iceberg v3 is a major step towards this goal. Iceberg v3 brings parity to the data layer, syncing deletion vectors, row lineage, VARIANT data type, and geospatial types. This ensures that customers can interoperate across Delta and Iceberg without needing to rewrite data. Through unification, Databricks will bring all the functionality of Managed Iceberg tables, including writes from external Iceberg engines, to Managed Delta (and vice versa).
Your Decision Framework
In the very near future, there will not be a ‘decision’ to be made because Delta and Iceberg will be fully unified. Until then, you can use the following to help guide your choice:
Choose UC Managed Delta when:
- Performance is critical (most ETL and analytics workloads)
- You want the most mature feature set today
Choose UC Managed Iceberg when:
- You have existing Iceberg writers (Flink, Trino) that need direct write access
- You require specific Iceberg features (such as Partition Evolution for dynamic partition schemes)
Never choose:
- Proprietary formats that lock you into a single vendor
- Solutions that require data duplication for interoperability
Path B: The Great Migration
"I need to escape my current platform."
Whether you're reacting to Snowflake's opaque consumption pricing, BigQuery’s architectural limits, the constraints of a legacy ecosystem, or simply tired of vendor lock-in, migration doesn't have to be a painful, disruptive, big-bang event.
Using Koantek’s award-winning X2D™ (“Anything to Databricks”) Migration Framework, built from years of successful enterprise migrations, you can de-risk the move, prove value early, and regain control of your data and budget.
Koantek’s Migration in Action
We’ve delivered these phased migrations at scale, reducing time-to-value by up to 60% for enterprise clients without disrupting business operations.
From Snowflake: The "Hollow Out" Strategy
Snowflake will tell you they support Iceberg. What they won't emphasize is that only Snowflake compute can write to Snowflake-managed Iceberg tables. This quasi-openness is vendor lock-in with extra steps.
Snowflake to Databricks in Three Phas

From BigQuery/Fabric: Leveraging Federation
These platforms are even more problematic because they don't even pretend to support open writes to Iceberg. Your data is trapped unless you explicitly export it, but the strategy remains the same.
From Trino/Presto Shops: Keep Your Tools, Upgrade Your Platform
This is the easiest migration. Your existing Trino clusters can now write directly to Unity Catalog-managed Iceberg tables via the Iceberg REST API. You get:
- Continued use of familiar tools
- Databricks' performance for heavy lifting
- Unified governance and security
- Gradual transition at your pace
Path C: Adding Iceberg to Your Databricks Stack
"I'm already using Databricks but need Iceberg support."
Welcome to the future. As a current Databricks user, you're perfectly positioned to leverage the best of both worlds.
For organizations already using Databricks, Koantek helps evaluate where UniForm suffices versus where native Iceberg tables are required, balancing performance, governance, and ecosystem fit.
When Native Iceberg Makes Sense
While UniForm solves 80% of use cases, native Iceberg tables shine when:
- External Writers Are Critical
- Your Flink jobs need direct write access
- Partner systems publish data in Iceberg format
- Ecosystem Requirements
- Your organization standardized on Iceberg
- Regulatory requirements specify open formats
UC Managed Iceberg: What's New in June 2025
Databricks’ latest enhancements bring Iceberg to full enterprise readiness:
- Write Interoperability with REST writers
- Governance Parity across Delta and Iceberg via Unity Catalog
- Cloud-native access via OpenAPI and REST for external catalogs
- Coming soon: Row Lineage for Incremental Processing – Iceberg tables now record immutable row IDs and last-modified sequence numbers, enabling low-latency change data capture (CDC), materialized view refresh, and cost-effective streaming downstream.
Unified Governance Across Formats
The beauty of Unity Catalog is that it doesn't care about formats. Your governance policies, lineage tracking, and access controls now work identically across:
- Native Delta tables
- UniForm-enabled tables (readable as Iceberg)
- UC Managed Iceberg tables
- External Iceberg tables from other systems
Snowflake, AWS, Starburst, and Google have each taken steps toward similar neutrality with their own Iceberg REST catalogs; however, Databricks remains the only major vendor that allows you to create, govern, and optimize both leading open formats from a single runtime. Moreover, Unity Catalog was designed from the ground up to govern not just data, but the full spectrum of data and AI assets (including ML models, files, and notebooks), providing a unified governance plane that others are still striving to achieve.
One catalog to rule them all.
Get Expert Help
Koantek is the go-to partner for Iceberg success. Backed by Databricks Ventures and trusted by enterprise clients across industries, we provide and offer:
- Free migration assessment and TCO analysis
- Proof-of-concept support and MVP acceleration
- Proven playbooks from successful migrations
The Bottom Line
The format wars are over. The winners are all of us who insisted on open standards. The losers are the vendors still clinging to proprietary formats and hoping you won't notice.
Iceberg v3 removes many of the remaining incompatibilities (delete‑vector encoding, row‑tracking semantics, VARIANT schema) between Delta and Iceberg, so platform choice is of far more importance than format choice.
Databricks is the only platform that enables you to create, govern, and optimize Delta and Iceberg side by side, with open governance and open APIs.
So, whether you're Team Delta, Team Iceberg, or Team "I just want my data to work everywhere," Databricks has you covered.
The real question isn’t if you’ll adopt open formats. It’s whether you’ll lead the charge or be dragged along later. In our experience, leaders ship faster and save millions. The followers pay with complexity, cost, and technical debt.
Ready to start your journey? Contact the Koantek team at sales@koantek.com for a free assessment of your migration options. As a Databricks Ventures portfolio company, we bring deep platform expertise and proven migration playbooks to accelerate your success.




