

.png)
.png)

.png)
Gartner predicts 40% of enterprise applications will feature task-specific AI agents by 2026, up from less than 5% in 2025 [1]. McKinsey estimates that generative AI could unlock between $2.6 trillion and $4.4 trillion in additional annual value across industries [2]. Only 23% of organisations are actively scaling AI agents in even a single business function [9]. AI agents generate extraordinarily valuable operational data such as retrieval scores, evaluation outcomes, routing decisions, tool call patterns, yet most organisations discard these signals or lock them in fragmented systems.
Agent Bricks
Agent Bricks is Databricks' framework for building production AI agents [4]. Users describe what the agent should do and Agent Bricks handles model selection, optimisation, and evaluation. What makes Agent Bricks unique from a data perspective is not what it does, but what it produces.
Knowledge Assistant
The Knowledge Assistant is purpose-built for document retrieval and question answering, delivering 70% higher answer quality than basic RAG approaches and a 15% improvement over sophisticated in-house solutions with reranking [6,10]. Behind that quality is a rich set of operational signals:
- Retrieval traces: which chunks were retrieved from which source documents, and the relevance score for each
- Reasoning chains: the "View thoughts" and "View trace" inspection data that captures how the agent arrived at its answer
- AI Judge assessments: built-in judges evaluate every response for correctness, groundedness, chunk relevance, safety and a pass or fail score
- SME feedback: subject matter experts can provide natural language feedback that is captured as structured labelled data
Supervisor Agent
Orchestrates multiple specialised agents, routing tasks to the right sub-agent [7]. From a data perspective, it produces:
- Routing decisions: which sub-agent was selected for each task and the reasoning behind the selection
- Sub-agent performance: latency, success rate, and token usage per child agent
- Coordination patterns: whether sub-agents ran sequentially or in parallel, retry behaviour, and cross-agent context flow
MCP Tool Integration
Agents discover and use tools via the Model Context Protocol, with a marketplace of pre-built integrations [8]. Every tool call generates:
- Structured call logs: tool name, arguments passed, and result returned
- Latency and status: how long each tool call took and whether it succeeded, failed, or timed out
- Usage patterns: which tools are called most frequently, which fail most often, and which consume the most time
Agent Bricks includes Agent-as-a-Judge evaluation, tunable judges, and synthetic data generation for testing agent quality at scale [4]. This evaluation layer produces Per-request judge scores, aggregate metrics on requests and Auto-optimisation data generated by hyperparameterizing and comparing models.
Lakebase
Lakebase is Databricks’ PostgreSQL database built directly on the lakehouse [3]. It became Generally Available in February 2026. Since its public preview in June 2025, adoption has grown at more than 2x the rate of Databricks' data warehousing product, signalling strong enterprise demand for operational databases that live natively on the lakehouse [5].
For handling agent operational data, some of its standout features are:
- Postgres compatibility: use any Postgres client, ORM, or library to write agent logs
- pgvector support: store and query embeddings natively alongside operational data
- Unity Catalog governance: access controls, lineage tracking, and audit logs in the same catalog as your tables, models, and agents
- Autoscaling: pay per use, zero cost when agents are not active
- Lakehouse Sync integration: data written to Lakebase is immediately queryable from the lakehouse.
In a traditional setup, agent operational data sits in an external database disconnected from analytics, and getting insight requires ETL plumbing, a separate governance layer, and ongoing maintenance. With Lakebase, the agent writes via a standard Postgres connection and the data team can query it with SQL in the same moment. Downstream Lakeflow Spark Declarative Pipelines (SDP) automatically transform that data into metrics, refreshing dashboards without manual intervention.
Architectural Design
Here is how the entire system fits together, from a user asking a question to a leadership team making investment decisions based on agent performance data.
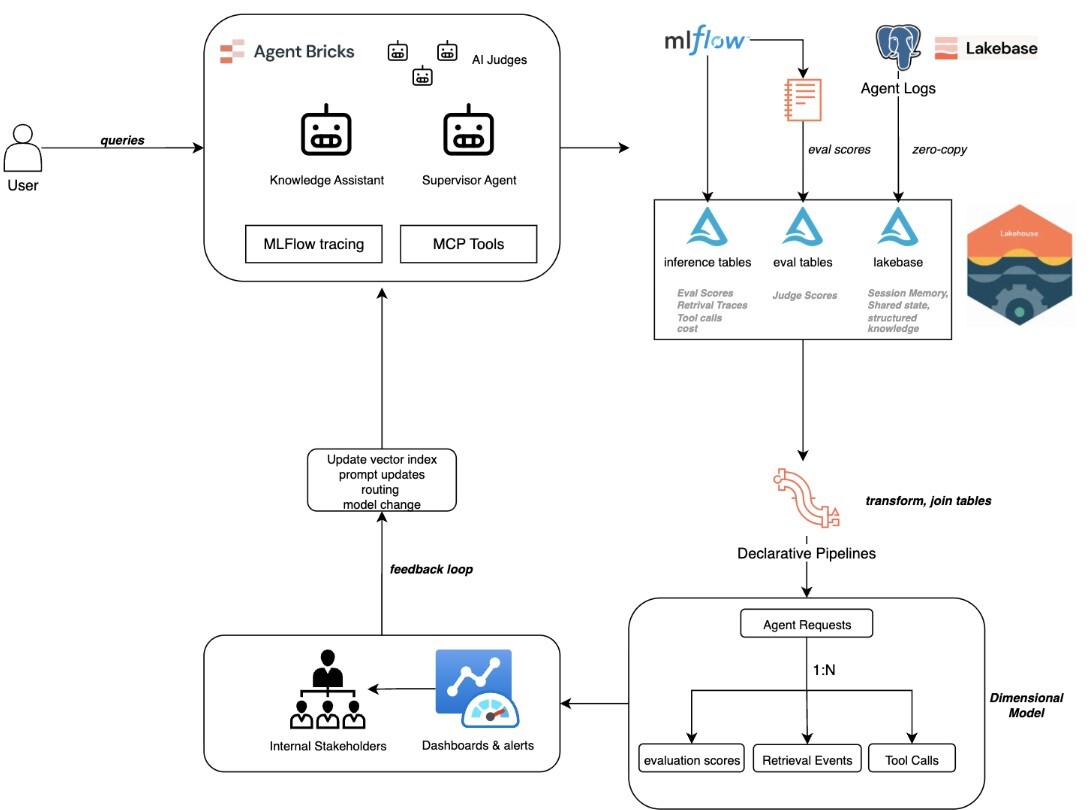
1. Request and Signal Generation
A request arrives at an Agent Bricks agent. The Knowledge Assistant retrieves chunks from its vector index with relevance scores captured via MLflow tracing. AI Judges evaluate the response for correctness, groundedness, chunk relevance, and safety, each with a pass/fail score and rationale. A Supervisor Agent, if involved, logs its routing decision and sub-agent performance. MCP tool calls are logged with arguments, results, latency, and status.
2. Data Lands in Two Places
The data follows two paths, both ending in the lakehouse:
- Inference tables and MLflow traces. Three automatically-created Delta tables contain every request, response, MLflow trace and human feedback. Evaluation judge results from mlflow.evaluate() can be written to additional Delta tables.
- Lakebase transaction data. The agent's runtime state, including conversation memory, session context, structured knowledge lookups, and shared multi-agent state, writes to Lakebase via a standard Postgres connection. This data is available in the lakehouse via Lakebase's Lakehouse Sync integration with no ETL required.
3. Lakeflow Spark Declarative Pipeline Builds the Observability Data Model
The raw data from both paths is now in the lakehouse, but it is not yet analytically ready. An SDP parses, flattens, and joins this raw data into a structured observability model, easing the process for setting up ETL with automated table creation and scaling.
The data model shown in Figure 1 describes the target schema that the pipeline produces.
- Agent Requests: The central fact table. Every retrieval event, evaluation score, and tool call links back to a specific request via a request ID key. This table is central for the model and enables cross-analysis per interaction.
- Retrieval Events: Parsed from MLflow trace spans, capturing which document chunks were retrieved, their relevance scores, and which were ultimately used in the agent's response.
- Evaluation Scores: Sourced from MLflow evaluation runs, capturing each AI judge's verdict (pass/fail), the judge type (correctness, groundedness, chunk relevance, safety), and the written rationale behind each assessment.
- Tool Call: Extracted from tool trace spans, including the tool name, input arguments, output result, latency, and success or failure status for every external tool invocation.
Most agent state tables store what the agent said. This model captures what the agent did, how well it did it, what evidence it used, and how long it took. This process transforms the agents’ log data into a data product.
4. Aggregated Metrics for Decision Making
On top of the observability model, the same SDP produces aggregated metric tables that are optimised for dashboards and alerting:
- Retrieval quality by day and source: average relevance scores broken down by agent, source document, and date. A declining trend on a specific source signals that the underlying documents are outdated or the vector index needs retraining.
- Evaluation trends: pass rates by judge type over time. If the groundedness judge starts failing more often, the agent may be hallucinating more, possibly due to a model update or a change in the knowledge base.
- Cost per resolution: total tokens and estimated cost per completed conversation session, broken down by agent. This is how you justify AI spend with data rather than intuition.
- Failure points: questions that consistently fail evaluation, grouped by agent and judge type, with sample queries and the judges' written rationales. It tells you exactly what is going wrong and why.
Metric tables refresh automatically as new agent interactions flow through the pipeline.
5. Dashboards Surface Insights
The metric tables power a Databricks Dashboard with panels that answer the questions leadership actually asks: Which knowledge sources are underperforming?What does each agent cost per resolved conversation? Where are our agents failing, and why? Each panel is backed by the corresponding fact/metric table, so the answers are a query away instead of a week-long reporting commitment.
6. Insights Feed Back into Agent Configuration
Dashboard insights flow back into agent configuration and turns a monitoring system into a continuous improvement system:
- Declining retrieval relevance signals knowledge base issues triggers a vector index refresh before users complain
- Evaluation failure rates pinpoint prompt weaknesses
- Sub-agent latency exposes routing inefficiencies
- Tool failure rates trigger remediation
Reviewing the Architecture
Three properties make this architecture work at enterprise scale:
- Unified governance. Agents, MLflow traces, Lakebase state, the observability model, the pipeline, and the dashboards all share a single Unity Catalog access control and lineage model.
- No cross-system ETL. MLflow traces land directly in the lakehouse and Lakebase state is surfaced via synced tables, so the only transformation is the SDP within the lakehouse.
- Horizontal scale. Each new agent is automatically captured by the same pipeline and dashboards, and the Supervisor Agent can orchestrate agents across departments using shared Lakebase state with ACID transactional guarantees [7].
Shipping This Pattern Without Building It From Scratch
Every component above is buildable, but most platform teams don't have the runway to assemble schemas, synced tables, pipelines, dashboards, and supervisor controls from a standing start, and then operate them. That's the gap Koantek built Ascend AI AppBase to close: a family of production-ready application templates that encapsulate Databricks best practices as generated code, including Unity Catalog governance, LakeBase schemas, synced tables, and single-bundle Databricks Asset Bundle CI/CD.
The template that matches this architecture is the AI Agent Operations Center. It delivers the pre-built implementation of the pattern described above: a fleet-level observability dashboard (per-agent latency, token and cost drill-down, MLflow trace deep-links, quality trends, live failed-thread feed) paired with a human-in-the-loop Supervisor Console (interactive routing topology, granular controls, version history with one-click rollback, and a full audit trail of routing decisions). It works with any LangGraph deployment, so you can adopt it alongside whatever you've already built.
It also fits into a larger Koantek value chain: Agent Factory builds and scaffolds agents, Agent Bricks and Lakebase deploy and run them, and AppBase AI Agent Operations Center manages and observes them.
What This Means for Enterprise
For the CFO: The finance team can see exactly what each agent costs per use case. If an HR Knowledge Assistant handles 2,000 queries a month at $0.05 each, replacing $15 help desk tickets, that is a quantifiable saving of $29,900 per month from a single agent. If an agent costs more than the process it replaced, you see it immediately.
For Operations: Continuous evaluation scores catch quality degradation before users do, shifting agent management from reactive to proactive.
For Compliance: The audit trail is a byproduct of normal operation. Every request resides in Unity Catalog, so regulatory reviews are a SQL query, not a week-long exercise.
Getting Started
If you're building AI agents on Databricks today, this pattern is available to you now. Agent Bricks and Lakebase are both Generally Available, and the operational signals described here are captured by default. The path is: deploy an Agent Bricks agent, point its state at Lakebase, build an SDP on the signals already flowing into your lakehouse, and connect a dashboard.
If you'd rather not assemble it from scratch, Koantek's Ascend AI AppBase AI Agent Operations Center delivers this pattern as a governed, single-DABs-bundle deployment in 1–2 weeks instead of the typical 6–8. Reach out to the Koantek team to see the template and the reference architecture.
Conclusion
The most valuable thing AI agents produce is not answers, it is operational data about how they produce those answers. That data is the foundation for every business outcome described above. The feedback loop highlights areas of improvement within the business, be it quality of documents, operations, or systems. The organisations that will lead in agentic AI are the ones that know which agents are working, which are not, why, and what to do about it.
Sources
[1] Gartner, "Gartner Predicts 40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026, Up from Less Than 5% in 2025," August 2025. https://www.gartner.com/en/newsroom/press-releases/2025-08-26-gartner-predicts-40-percent-of-enterprise-apps-will-feature-task-specific-ai-agents-by-2026-up-from-less-than-5-percent-in-2025
[2] McKinsey & Company, "Seizing the Agentic AI Advantage," 2025. https://www.mckinsey.com/capabilities/quantumblack/our-insights/seizing-the-agentic-ai-advantage
[3] Databricks, "A New Era of Databases: Lakebase." https://www.databricks.com/blog/what-is-a-lakebase
[4] Databricks, "Introducing Agent Bricks: Auto-Optimized Agents Using Your Data." https://www.databricks.com/blog/introducing-agent-bricks
[5] Databricks, "Databricks Lakebase is now Generally Available," February 2026. https://www.databricks.com/blog/databricks-lakebase-generally-available
[6] Databricks, "Agent Bricks Knowledge Assistant Is Now Generally Available: Turning Enterprise Knowledge into Answers.
"https://www.databricks.com/blog/agent-bricks-knowledge-assistant-now-generally-available-turning-enterprise-knowledge-answers
[7] Databricks, "Agent Bricks Supervisor Agent is Now GA: Orchestrate Enterprise Agents.
"https://www.databricks.com/blog/agent-bricks-supervisor-agent-now-ga-orchestrate-enterprise-agents
[8] Databricks, "Accelerate AI Development with Databricks: Discover, Govern, and Build with MCP and Agent Bricks.
"https://www.databricks.com/blog/accelerate-ai-development-databricks-discover-govern-and-build-mcp-and-agent-bricks
[9] McKinsey & Company, "The State of AI in 2025: Agents, Innovation, and Transformation," November 2025.
https://www.mckinsey.com/~/media/mckinsey/business%20functions/quantumblack/
our%20insights/the%20state%20of%20ai/november%202025/the-state-of-ai-2025-agents-innovation_cmyk-v1.pdf
[10] Databricks, "Instructed Retriever: Unlocking System-Level Reasoning in Search Agents.
"https://www.databricks.com/blog/instructed-retriever-unlocking-system-level-reasoning-search-agents
.png)
.png)

.png)