

.png)


.png)
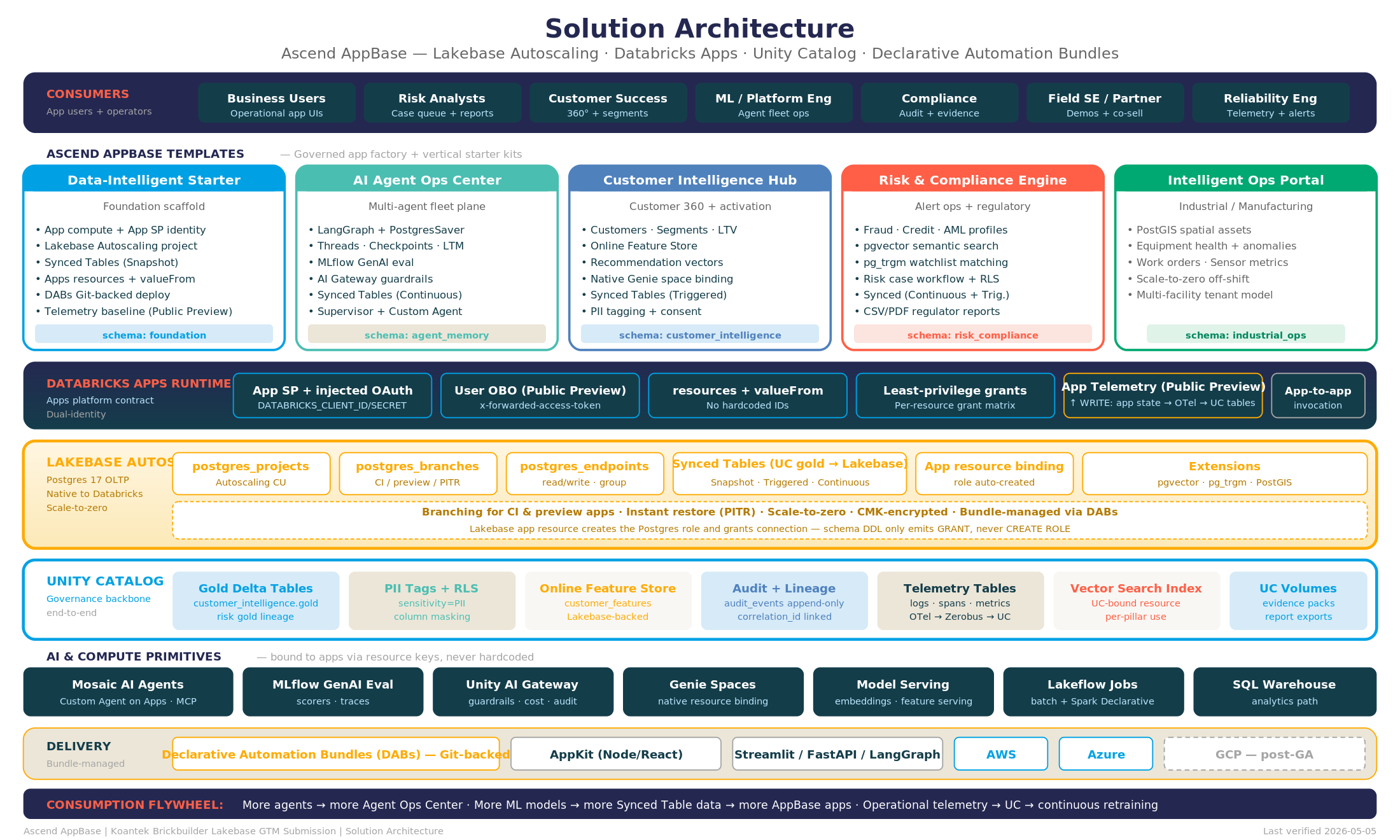
Databricks now ships everything an operational app needs. Databricks Apps host the app. Lakebase gives it transactional state and low-latency serving of lakehouse data. Synced Tables move governed Unity Catalog data into Lakebase. Apps resources bind the dependencies and keep the app portable, and Declarative Automation Bundles ship it. The primitives are there.
The gap is turning them into something a field team can deliver, review, and hand to a customer the same way every time. Ascend AppBase is how we close it: a productization of Databricks Apps and Lakebase best practices into repeatable, governed operational-app delivery patterns. AppBase is a growing library of Lakebase-first kits on a shared Data-Intelligent Starter foundation, four shipping today, plus the conventions we apply on every engagement so the app, its state, and its governance line up.
The gap between a primitive and a pattern
The pieces are right. The work is in the assembly: turning those primitives into an app a field team can deliver, review, and hand to a customer the same way every time.The same three things slow most engagements down.
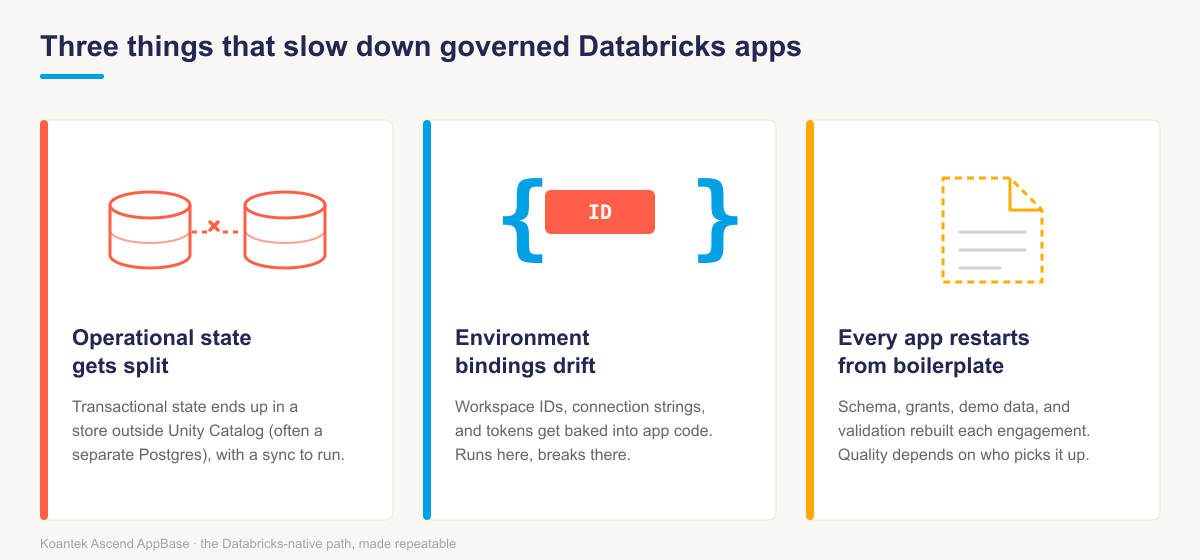
The first is operational state getting split. The app reaches for a store outside Unity Catalog, data gets copied into it, and the workspace ends up with a second access model and a sync nobody scheduled. A separate Postgres next to the lakehouse is the common version.
The second is environment bindings drifting. App code carries workspace IDs,connection strings, and tokens. It runs in one workspace and breaks in the next, so moving it through dev, staging, and a customer environment becomes a rewrite.
The third is every app restarting from boilerplate. Each operational app reinventsthe schema, the grants, the demo data, and the validation. Quality depends on whichengineer picks it up.
If you have shipped an operational app on Databricks, you have met at least one ofthese. AppBase is what addressing all three at once looks like once you have made it repeatable.
The kit library, on a shared foundation
Four kits ship today on one shared foundation, all governed by Unity Catalog. The library is built to grow.
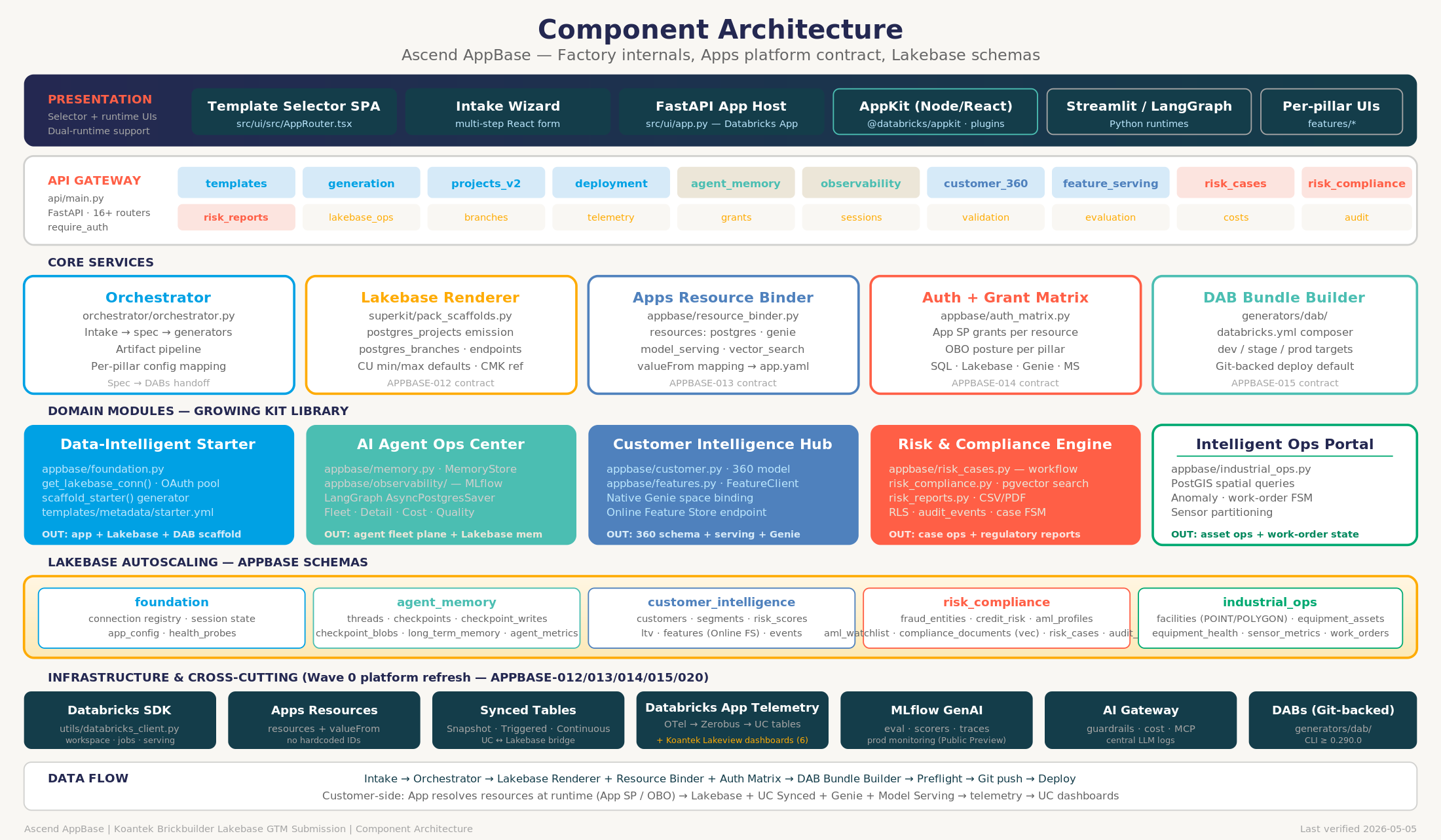
The foundation: Data-Intelligent Starter
The Starter is the Lakebase-first baseline every kit builds on. It is a Databricks App, a Lakebase Autoscaling project, a Unity Catalog grant matrix, app resource bindings, value From runtime config, DAB targets, and the Synced Tables wiring from gold into Lakebase.
The part that matters most here is the portability contract. Databricks Apps resources bind Lakebase, Genie, SQL warehouses, and secrets to the app, and app.yamlvalue From resolves those values at runtime. The generated app holds no workspaceIDs, no connection strings, and no tokens. That is what lets the same kit move across workspaces and clouds without an edit.
Every kit starts from the Starter, so the conventions only have to be right once.
1. Customer Intelligence Hub: serving and state in one place
Customer Intelligence Hub is the governed Customer 360 pattern. Synced Tables move gold customer data from Unity Catalog into Lakebase, where the app reads it with low latency. The same Lakebase instance holds the app’s own transactional state: notes, statuses, the workflow the user is moving through.
That is the shape I keep coming back to. The app reads governed serving data and writes its own state in one Lakebase Postgres. Unity Catalog governs the source and synced data; Lakebase holds the operational state under a Databricks-managed app identity and resource bindings. Genie binds in as an app resource where the customer wants conversational query over the same data, so it is a governed binding rather than a hand-written query service.
The kit ships with synthetic Customer 360 data, consent-aware views, feature freshness cues, and masked-safe fallback, so a field team can replay the whole pattern before any real customer data is involved.
2. AI Agent Operations Center : agent memory that you can read
Agent Operations Center is the Lakebase-backed operator plane for agent workloads. Databricks documents Lakebase as a backend for stateful agents, and this kit puts that to work: conversation state, checkpoints, tool-call records, and review state all live in Lakebase tables an operator can inspect.
The reason to keep agent state in Lakebase instead of a separate store is the same reason as the customer kit. The state stays under Unity Catalog governance, the app runs under its own service principal, and the evaluation handoff to MLflow and AI Gateway stays visible inside the app. An operator can open a review queue and read exactly what an agent did and why.
3. Real-Time Risk & Compliance Engine : cases, alerts, and evidence
The Risk & Compliance Engine is the Lakebase pattern for alert queues, case state,and audit evidence. Synced Tables keep governed risk scores and entities available to the app. Lakebase holds the transactional case and review state. pgvector handles semantic retrieval over policy and evidence text, so a reviewer can pull the relevant policy alongside a case without leaving the governed app.
Branch snapshots are useful here. A reviewer can work a case set against a Lakebase branch and roll back with instant restore, which gives compliance teams a clean way to review and replay decisions.
This kit stays demo-scoped with synthetic alert and case data. Regulator-ready exports and any audit-outcome claim wait for customer and legal sign-off.
4. Intelligent Operations Portal: operations state and alerts
The Operations Portal applies the same pattern to industrial and asset-heavy teams. Synced Tables move governed operational scores and asset data from Unity Catalog into Lakebase. The app holds the operational state on top: work-order status, asset records, and the alert queue an operator works through.
It uses the Risk kit’s architecture for an operations domain. Lakebase holds the transactional state, Synced Tables keep the governed source data current, and branch snapshots let a site team review a change against real-shaped data before it ships.The kit ships with synthetic operations data, so a field team can replay it before any plant data is involved.
These four kits ship today. The library is built to grow: a new kit is a new domain on the same Starter foundation, inheriting the governance, bindings, and delivery contract, so the next one does not start from boilerplate.
Three things building these kits taught us
1. The portability contract is the whole game
The single change that makes a kit reusable is moving every environment-specific value out of the code and into Databricks Apps resources and valueFrom . When theapp carries no workspace IDs or connection strings, promoting it from our workspaceto a customer’s is a deploy. When it does carry them, every environment is a smallrewrite, and the kit stops being a kit.
We treat a clean app.yaml with no hardcoded resource values as a gate on theStarter. If it does not pass, nothing downstream is portable.
2. Put the state next to the serving data
The version of this architecture that works keeps the read-only serving data and the transactional app state in the same Lakebase Postgres, fed by Synced Tables from gold. The app makes one connection. There is one access model. There is no second system to back up and no sync job to babysit.
Most of the operational complexity I used to see on these apps came from the gap between the analytical store and the app’s own database. Closing that gap with Lakebase removed a category of work.
3. Branch-aware previews change how reviews happen
Lakebase branching is the feature I did not expect to lean on as much as we do. A branch plus an app preview lets a reviewer see a change against real-shaped data, and instant restore makes rollback a non-event. Reviews stopped being a conversation about a screenshot and became a thing you click through against a live branch.
For regulated workflows in the Risk and Operations kits, that branch-and-restore loop is also how we keep a review reproducible.
Where we go from here
The kits ship today on synthetic data and branch-local validation, packaged as Declarative Automation Bundles. App telemetry is Public Preview, so we treat it as non-blocking: where the workspace and region support it, telemetry writes logs,metrics, and traces to Unity Catalog tables, and where it does not, the kits fall back to app logs with the same governance story.
We are a Databricks Brickbuilder Partner, and AppBase is part of our Q2 FY27 Databricks Lakebase GTM partnership. Dev Hub and AppKit are complementary here.They help a developer scaffold a Databricks app; AppBase packages the Lakebase first delivery layer around that, with the schemas, grants, demo data, and validation afield team needs to deliver the same result twice.
If you are running Databricks and trying to figure out where your operational appstate should live, we would be glad to compare notes. We have built the pattern, the kits are inspectable on synthetic data, and the delivery bundles are reproducible.
Eddie Edgeworth owns Ascend AppBase at Koantek, a Databricks Brickbuilder Partner. He has built data and application platforms across financial services, manufacturing,and life sciences. Find him at koantek.com or partners@koantek.com.
.png)
.jpg)
.png)