
Real-Time, Data-Driven Decision-Making with Databricks
Data has become a crucial strategic asset for organizations in today’s rapidly changing business landscape. However, simply having data is not enough to drive successful decision-making and increase profitability. This blog will explore the importance of leveraging data-driven insights to maximize value and drive strategy to increase the success of your business. By accelerating the time to value your data, organizations can stay ahead of the competition and achieve their goals. Whether you’re in finance, healthcare, retail, or any industry, the principles discussed in this blog will provide valuable insights for organizations looking to get the most out of their data.
Over the past decade, several trends have disrupted the Data & AI landscape, requiring traditional data platforms needing to evolve to support changing needs and opportunities, including:
- Capitalizing on data in all its variety, sizes, and forms and applying it to analytic use cases (data science, artificial intelligence, and machine learning)
- Combining traditional deductive and reactive (past-looking) analytics with forward-looking predictive and prescriptive analytics
- Performing reverse ETL (delivering data to consumers in their chosen consumption pattern (e.g., API, BI Tool, queue, specialized Analytic Engine)
- Factoring the above into real-time decision-making
Companies are at varying levels of maturity concerning the above requirements. Many have moved away from legacy data warehouse platforms that are no longer suited to these emerging needs onto cloud-based modern architectures and platforms. Additionally, many have incorporated a shift from high latency, nightly batch processing to near real-time, low latency streaming processing. Some have gainfully deployed artificial intelligence into production workflows. Finally, nearly all are still figuring out how to institutionalize, perfect and harden these capabilities.

(Figure 1. Modern Data Pipeline Maturity )
An emerging data management trend is treating data like a product. (HBR: A Better Way to Put Your Data to Work).
When data is considered a strategic asset, it should be packaged with the same attention and rigor as traditional products and services. Data should be viewed holistically to include the following:
- Product Management (and product roadmaps)
- Data Consumers and established consumption patterns (including self-service)
- Data Product teams (engineers, scientists, modelers, architects, DevOps)
- Data Pipelines & Code
- SLAs, Data Provenance, and Data Quality
- Security, Governance, Discovery, and Observability
- Monetization
Wherever your company is in this journey, the true backbone and enabler of organizational data continue to be the data pipeline. With these trends, data pipeline requirements have become more complex and critical. Modern data pipelines and platform architectures must support all the use cases listed above and wrap these capabilities into production-grade pipelines. The inability to do so could create vulnerabilities or deficiencies in your enterprise data strategy, making you less competitive.
Regardless of the current state of your enterprise data, companies can take either incremental steps or leaps up the maturity curve; the further up the curve you are, the more return you get from your data modernization efforts. Digital natives know that there are exponential returns contained in real-time analytics.
The Databricks Lakehouse is ideally suited to support these emerging requirements and unify data engineering, data science, machine learning operations, and data governance in a single, collaborative platform.
Moreover, Databricks supports a wide range of data integration technologies, from open-source Spark to Databricks-managed offerings and partner tools, and even features these in the form of Databricks industry solutions.
The Ever-Increasing Pervasiveness of Real-Time, Data-Driven Decision-Making
Traditional (nightly) batch data pipeline approaches can no longer keep up with the speed of the business. Without real-time data, companies are forced to make (likely poorer) decisions without the information that would best support those decisions. Meanwhile, real-time streaming approaches can support data-driven decision-making and enable real-time data analysis, predictive algorithms, and artificial intelligence.
This section summarizes various real-time analytics examples and use cases by industry and illustrates the need for streaming data pipelines to keep pace with today’s fast-paced digital world. In future blogs, we will demonstrate the implementation of many of these capabilities within Databricks streaming workflows.
Retail
Forecasting consumer demand is a critical activity for retail companies. Profitability hinges upon accurately predicting product demand, ensuring they are in stock, and then ensuring they are accessible to customers when they are ready to buy. Underestimating demand results in missed sales and higher costs to remediate; overestimating results in higher carrying costs, unsold inventory, and waste.
Addressing this problem requires data pipelines to collect several sources of real-time data in order to produce data-driven insights, including:
- point-of-sale transactions
- inventory
- clickstreams
- other external data such as social media, news, and weather.
Modern data pipelines are often enriched with real-time artificial intelligence & machine learning to forecast demand, add personalization, make recommendations, and improve customer engagement and consumer outcomes.
Real-time processing benefits the entire retail value chain, including supply chain management, warehousing & inventory management, vendors, sales channels, and CRM. Seeing the current status of operations helps everyone involved to make better-informed decisions.

Manufacturing and Operations
An overarching goal for manufacturing companies is to accelerate essential data ingestion and turn it into insights supporting inventory, logistics, ERP, operations, and their products. Real-time data ingestion needs exist for ERP, SCM, IoT, social, and other sources to realize predictive AI & ML insights. Many companies use this data to create digital twins (a replica software model of a physical entity) to facilitate design, perform integration testing, and run simulations on those physical components.
Additionally, most manufacturing companies create massive sensor infrastructure for their operations or products, which generates enormous volumes of IoT data in the form of telemetry logs, images, etc. This data must be ingested in near real-time to monitor the health of equipment, infrastructure, and other assets.
Furthermore, manufacturing companies are often required to perform the following:
- real-time ingestion of transactions
- operational data
- inventory
- market and competitive data
This activity addresses analytic use cases around their markets, competitors, and customers. A modern manufacturing data pipeline collects this data in near real-time and often couples it with continuous analytics, AI & ML to perform predictive maintenance, anomaly detection, real-time workflow optimization, supply chain management, equipment effectiveness, and health & safety risk assessment.
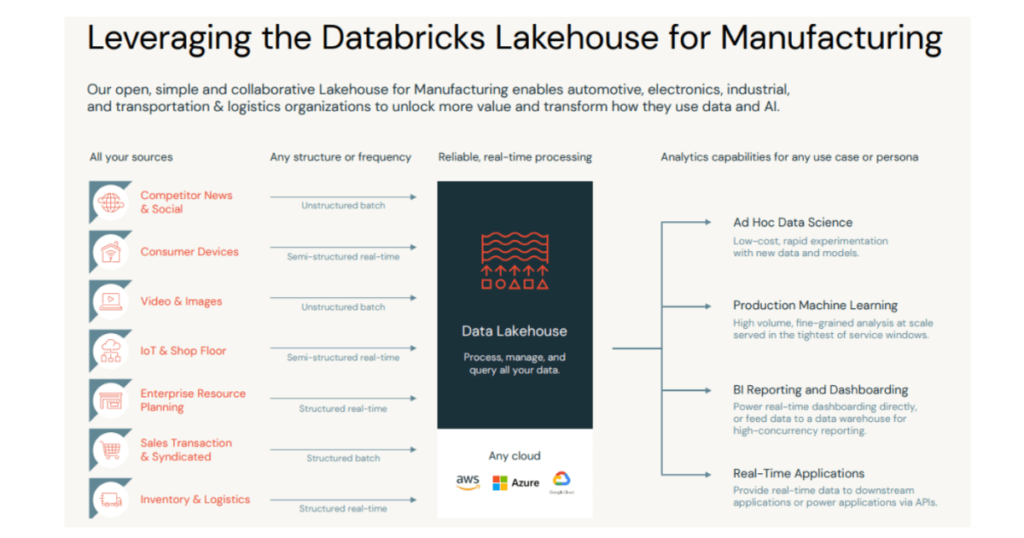
(Figure 3. Databricks Lakehouse for Manufacturing)
Financial Services
Consumers expect banking and financial applications to accurately and immediately reflect the up-to-the-minute status of their accounts. The best time to combat fraudulent activity is while those transactions are happening.
Streaming data pipelines collect
- transactional data
- market data
- trends
- merchant products and services
- clickstream data
- customer service data
The data-driven insights created with this information can be combined with AI to flag and combat fraud, make targeted recommendations and advertisements, predict customer churn, and aggregate risk.
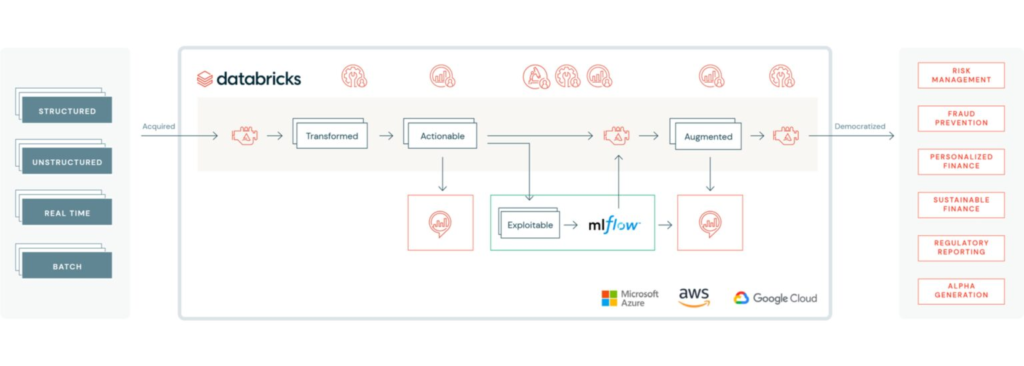
(Figure 4. Databricks Lakehouse for Finance)
Healthcare
Care providers must be able to monitor conditions continuously so that patients receive the timely interventions and care that they need.
Two significant objectives of healthcare companies are
- improve patient outcomes
- optimize the cost of care
The key to both is collecting and real-time monitoring of critical patient information (a 360-degree patient profile), including:
- vital electronic health records
- insurance claims
- medications
- medical monitors
- imaging
- lab reports
- genomic data
Intelligent data pipelines coupled with AI/ML can:
- shortened inpatient hospital stays
- aide in the pre-detection of life-threatening conditions
- build intelligent clinical alarm systems
- predict demand for hospital beds, supplies, and medications
Streaming facilitates CMS interoperability and data exchange with internal and external systems via FHIR.
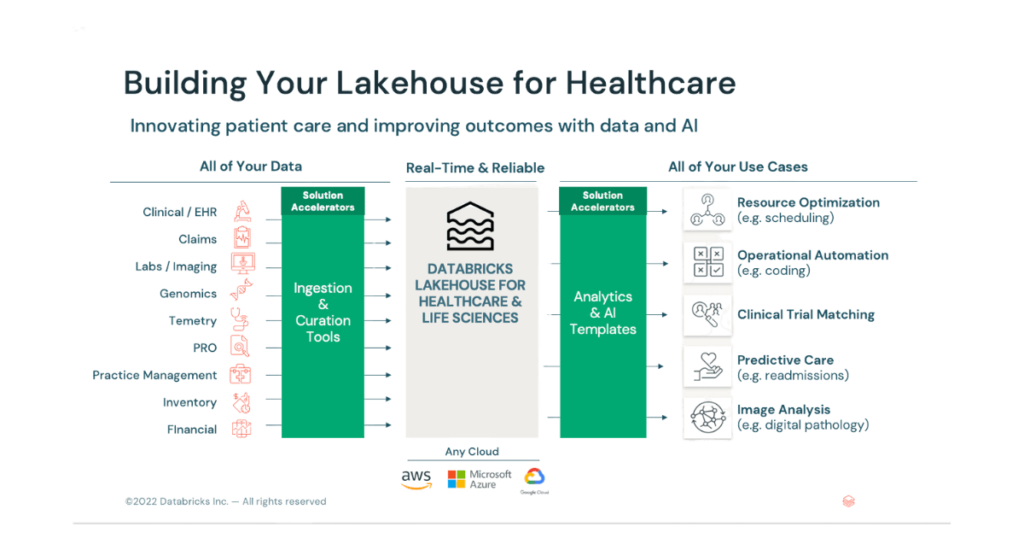
(Figure 5. Databricks Lakehouse for Healthcare)
Conclusion
In this article, we have shown how the requirements for modern data pipelines are both increasingly time sensitive and complex. They need to support data in its immediacy (velocity), format, and size requirement and augment it with analytics, data science, artificial intelligence, and machine learning to support business use cases. Finally, these pipelines need to operate at the speed of the business for there to be actionable data-driven decisions.



