


Databricks Vs. Microsoft Fabric: Evaluating Enterprise Readiness
With the recent general availability of Microsoft Fabric, we hear assertions suggesting it is (or will become) a preferred option over leading Data & AI Platforms such as Databricks. Some are confused about whether it is better to adopt one platform exclusively or to attempt to use both in some sort of hybrid approach. Both provide a wide array of features for data management, including Data Integration, Engineering, Warehousing, Analytics, and AI/ML and there is considerable overlap. In this analysis, we will provide context and find a resolution in the question of which is more favorable: Databricks vs Microsoft Fabric.
Databricks, the established incumbent and pioneer of the unified Lakehouse, has been a trailblazer in this field combining data lake and warehouse features. Microsoft Fabric, a rebranding and integration of Synapse and other existing Azure services, is Microsoft’s new Lakehouse platform offering. It is important to look beyond marketing hype and assess whether Fabric is truly ready for production enterprise workloads.
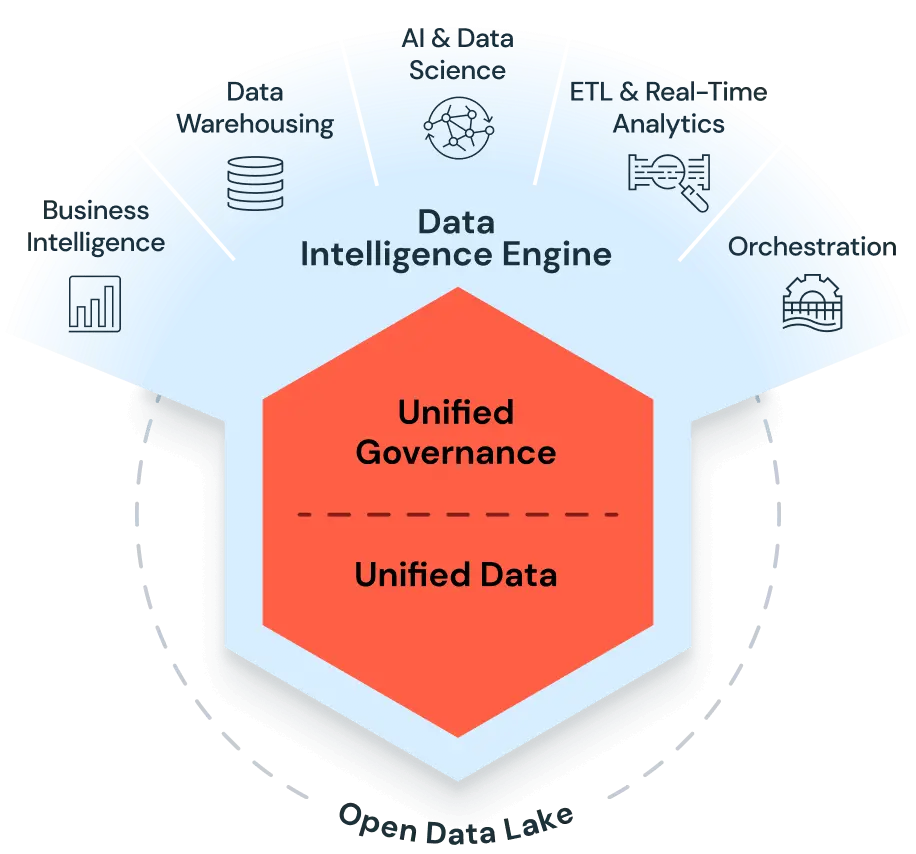
Source: Databricks

Source: Microsoft
In this blog, we offer our insights from working with clients using Databricks and Microsoft technologies. We assess these platforms on their current features, architecture, pricing, maturity, and compliance to help businesses make informed decisions.
Choosing the Right Foundation
While both sides of the Databricks vs Fabric clash share commonalities, their architectural approaches differ in terms of user experience and administrative control.
-
Compute and Cost
Fabric abstracts away underlying compute dimensions through consolidated “Capacity Unit” SKUs that bundle all its supported processing requirements. In other words, there is a single “dial” to turn whether the workload involves Apache Spark, Synapse Real Time Analytics, SQL, BI, Synapse Data Warehousing, or Synapse Data Science. Outside of this, there is limited ability to configure specific compute options.
In contrast, Databricks compute is a function of the specific workload (e.g. job compute, Databricks SQL, Model Serving, etc.). This allows for more granular control over decisions that affect cost and performance. Users can tailor instance types, node sizes, auto-scaling policies, and other compute parameters to match workload demands. For customers who need or prefer the simplicity of abstraction, Databricks serverless provides this.
Fabric’s capacity model introduces Smoothing and Throttling which complicates the single dial and can adversely impact workload performance. This results in a high likelihood that you are either paying extra for unused capacity or missing SLAs unless you are perfect at predicting variable demand.
Overall, the distinction means Fabric users sacrifice granular control which can lead to higher cost of ownership and inconsistent performance, while Databricks provides flexibility and configurable control of the options that affect performance and cost.
-
Data Persistence
The ultimate purpose of the lakehouse is to ingest and store analytics-ready data in open formats accessible to various engines. Fabric and Databricks are each backed by cloud object stores. Fabric builds its OneLake on Azure Data Lake Storage (ADLS) Gen2, which leverages the Delta Lake open format built and open-sourced by Databricks. Databricks is multi-cloud and runs on all major cloud-hosted object containers including Amazon S3, ADLS Gen2, and Google Cloud Storage (GCS).
A significant difference between the platforms is how each allows for connectivity to external (or federated) data sources. These include external databases, cloud storage accounts, and other components such as Power BI, Azure Data Explorer, etc. without having to move them into Lakehouse storage. While some might say these sources represent somewhat of an anti-pattern for a unified lakehouse (contributing to data silos etc.) they are often a necessary fact of life.
Databricks Unity Catalog provides support for such sources via Foreign Catalogs, Volumes, and External Locations, all of which are fully governed and enforce object-level security. In Fabric, the same is accomplished via OneLake Shortcuts, which as of this writing, does not carry through the security and access policies established by the source.
-
User Interface & Experience
Databricks and Fabric each provide central management consoles offering a unified view and access through the concept of workspaces. These provide an integrated set of capabilities for data engineers, analysts, and data scientists that can break down user silos while at the same time guarantee necessary isolation and security.

Fabric distinguishes native functionality such as notebooks, Spark jobs, and pipelines and product experiences like Power BI and Synapse. Integration of distinct product experiences can take additional time and result in functionality differences until it’s complete. For example, some analytic flows in Power BI won’t function the same as they do when invoked within Fabric’s interface. This highlights the challenge of retrofitting pre-existing Azure services under the Fabric umbrella. This will affect users’ ability to build end-to-end data solutions until the integration is complete.
Databricks is a purpose-built environment that combines data engineering, data science, and analytics into a single experience. It is capable of integrating the same product experiences offered by Fabric via standalone Azure services (e.g. Azure Data Factory, Azure Machine Learning, Power BI, Azure Data Explorer, etc.), as well as offering other partner integrations (including Fivetran, dbt, Tableau and many others) through Databricks Partner Connect.
-
Cloud Infrastructure
Databricks is a first-party service on Azure and supports all 3 major cloud providers (Azure, AWS, and Google Cloud). This multi-cloud flexibility protects against Hyperscaler lock-in, permits infrastructure selection based on performance and costs, and allows for the distribution of workloads to different availability zones for disaster recovery. Microsoft Fabric is currently restricted to Azure, which may lock organizations into a single ecosystem and limit enterprise options and flexibility.
Governance and Compliance
The modern analytics platform requires a distinct new strategy to secure, track, monitor, audit, and serve the enterprise’s expanding variety of data products, models, and sharing. In the case of the battle of Databricks vs Fabric, Fabric’s vision of OneSecurity along with Purview integrations may address this need in the future. Fortunately for Microsoft customers, Databricks Unity Catalog delivers much of this fine-grained governance now. It is the heart of Databricks and has the functionality to secure all data assets in the platform, including tracing data lineage, enabling discovery, building a semantic layer, and accomplishing data classification, documentation, security, and fine-grained access control. Databricks is extending its leadership position by delivering the world’s first intelligent lakehouse and has infused AI throughout the platform, including AI assistants, performance optimizations, and natural language queries.

Source: Databricks
Microsoft Fabric currently requires integration with Purview, which has known functional limitations. These include limited administrative oversight, data collection issues, processing bottlenecks, data transfer delays, and other operational challenges. For Fabric Copilot to be able to realize its promise of establishing high-quality insights and AI capabilities, this integration needs to be seamless. Semantic knowledge on data and models, classical ML and now generative AI, must come from a unified governance capability.
Enterprise Readiness of Databricks vs Microsoft Fabric
This section lists a few other anecdotal points offering insight into the current readiness of Microsoft Fabric.
-
Performance Tradeoffs and Queue Management
Fabric does not currently partition capacity into distinct compartments with AI-driven or user-defined constraints or workload priorities. As a result, incoming analytical workloads may encroach upon one another (which could impede existing production workloads). These performance interferences may hamper business user productivity, contributing to missed SLAs.
-
Multiple engine disparity
Fabric treats lakehouses and warehouses as different entities. This means you have to choose one for any particular workload and manage them separately. For example, if your data resides in a warehouse, you cannot write to it with Spark.
-
GenAI and ML capabilities
Fabric does not contain GenAI and ML capabilities and has to be rounded out and augmented by other Azure services. These include Azure Databricks, Azure Machine Learning, and Azure AI Services. This results in additional silos, complexity, and integration points that make the development experience more difficult. Without these, Fabric lacks a natively integrated model registry, monitoring, model governance, real-time serving, and feature stores that enterprises require. These missing components for robust ML and LLMOps limit Fabric’s viability for scaling AI/ML and delivering models to production.
-
Deployment
Microsoft Fabric Lifecycle Management is in Preview. Fabric Deployment Pipelines have existing limitations and do not fully support all Fabric items. This introduces the problem that it may not be possible to fully automate continuous integration and deployment. For example, Fabric does not expose APIs for programmatic control over serverless resources, requiring manual administrative actions rather than automation or orchestration integration.
-
Data Sharing
Microsoft Fabric currently lacks native capabilities for secure and scalable Data Sharing across organizational boundaries.
-
Data Loading
Fabric data load wizard cannot reapply past configurations through its UI, forcing manual JSON pipeline edits later. This also limits usability versus scripting data loads directly.
-
Security and Secrets
Microsoft Fabric currently provides limited support for managed identities and integration with Azure Key Vault. This causes enterprise concerns around default security and secret management capabilities. We hope this will be improved soon.
Databricks vs Microsoft Fabric: At a glance
Our experience is that Microsoft Fabric is currently not ready for production workloads. The platform struggles with integration issues and the need to stitch together additional Microsoft services to overcome feature limitations. These limitations represent a tangible risk to you in several ways, including security, cost, complexity, and quality. Ultimately this makes it more challenging for your team to deliver quality products. In the meantime, if you have a small data silo with slowly changing data, Fabric is a great choice. This is because it can be used to begin learning about the power of the lakehouse for reporting.
With that, the battle of Databricks vs Microsoft Fabric has concluded. Databricks is and will remain the leader of the unified Lakehouse (and ever-expanding Data Intelligence Platform) for the foreseeable future. It continues to be the foundation for your Data & AI platform, especially when it comes to building enterprise-grade solutions. These solutions often require security, reliability, scalability, and automation, with common developer and user experiences. In conclusion, Microsoft Fabric and Databricks can be used together in the right circumstances. In contrast, Databricks has independently executed the lakehouse vision for thousands of customers. They also continue to innovate by expanding the open Databricks Intelligence Platform.



