
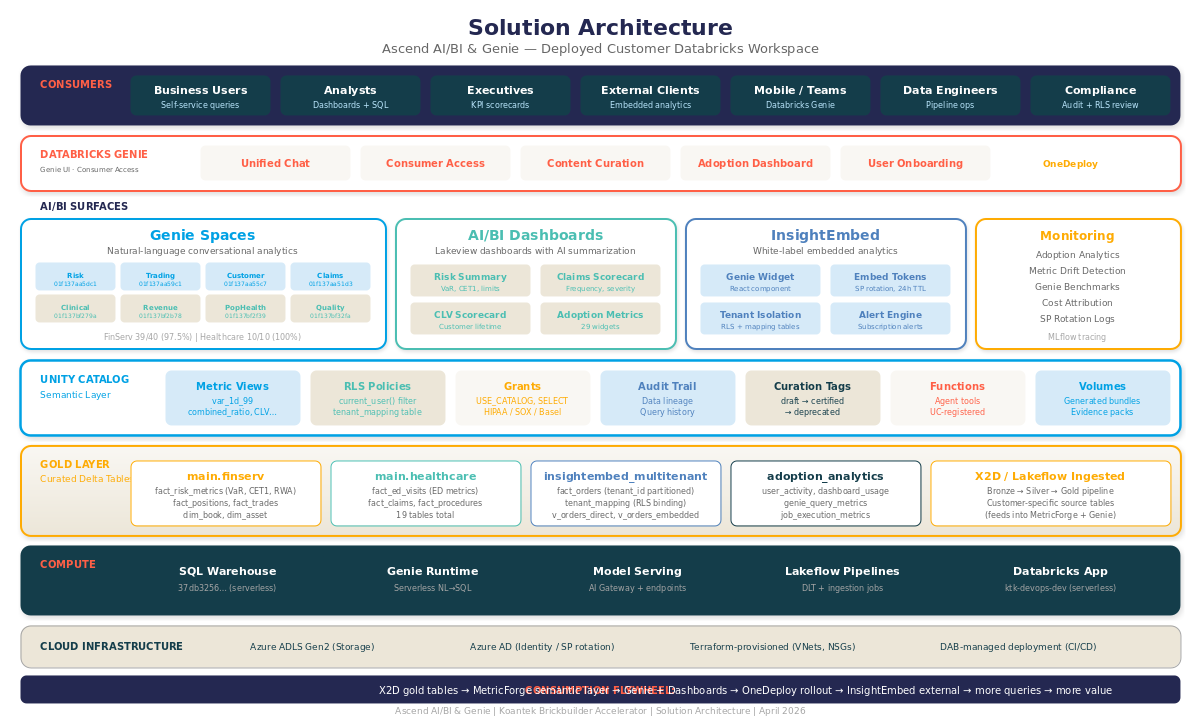
Productizing Databricks Genie at Enterprise Scale

.png)
Productizing Databricks Genie at Enterprise Scale
Summary
How we ship governed Genie spaces in roughly 3 days per domain, with an ≥80% benchmark gate at deploy.

May 4, 2026
Summary
How we ship governed Genie spaces in roughly 3 days per domain, with an ≥80% benchmark gate at deploy.

.png)
.png)
.png)
.png)